Protocolo BGP - Border Gateway Protocol
O Border Gateway Protocol (BGP) é um protocolo de
roteamento dinâmico usado entre sistemas autônomos (ASs).
Ao contrário de um IGP (Interior Gateway Protocol), como o OSPF (Open Shortest Path First) e o RIP (Routing Information Protocol), o BGP é um EGP (Exterior Gateway Protocol) que controla o anúncio de rotas e seleciona as rotas ideais entre os ASs, em vez de descobrir ou calcular rotas.
O BGP é classificado em dois tipos, de acordo com a sua localização:
BGP interno (IBGP)
BGP externo (EBGP)
Versões do BGP:
- BGP-1 (definido na RFC 1105);
- BGP-2 (definido na RFC 1163);
- BGP-3 (definido na RFC 1267) são três versões anteriores do BGP.
- O BGP-4 (definido na RFC 1771) é usado desde 1994. Desde 2006, as redes IPv4 unicast usam o BGP-4 definido na RFC 4271, e outras redes (como redes IPv6) usam o MP-BGP definido na RFC 4760;
- MP-BGP é uma extensão do BGP-4 e aplica-se a diferentes redes; no entanto, os mecanismos originais de troca e roteamento de mensagens do BGP-4 não são alterados. Os aplicativos MP-BGP em redes IPv6 unicast e IPv4 multicast são chamados BGP4 + e Multicast BGP (MBGP), respectivamente.
O BGP possui as seguintes características:
Usando várias extensões de
protocolo do BGP4, o BGP4 + é aplicável às redes IPv6 sem alterar os mecanismos
de mensagens e roteamento do BGP4.
MP-BGP
O BGP-4 convencional gerencia apenas as informações de roteamento unicast IPv4 e a transmissão inter-AS de pacotes de outros protocolos da camada de rede, como o multicast, é limitada.
Para oferecer suporte a vários protocolos da camada de rede, a Internet Engineering Task Force (IETF) estende o BGP-4 às extensões de multiprotocolo para BGP-4 (MP-BGP). MP-BGP é compatível com a frente. Especificamente, os roteadores que suportam MP-BGP podem se comunicar com os roteadores que não suportam MP-BGP.
Como um aprimoramento do BGP-4, o MP-BGP fornece informações de roteamento para vários protocolos de roteamento, incluindo IPv6 (BGP-4) e multicast.
O MP-BGP mantém rotas unicast e multicast. Ele as armazena em diferentes tabelas de roteamento para separar as informações de roteamento unicast das informações de roteamento multicast.
O MP-BGP suporta famílias de endereços unicast e multicast e pode construir a topologia de roteamento unicast e a topologia de roteamento multicast.
A maioria das políticas e configurações de roteamento unicast suportadas pelo BGP-4 pode ser aplicada ao multicast e o BGP-4 pode manter rotas unicast e multicast de acordo com essas políticas de roteamento.
Família de endereços
O campo Informações da família de endereços consiste em um AFI (identificador da família de endereços) de 2 bytes e um SAFI (identificador da família de endereços subseqüente) de 1 byte.
O BGP usa famílias de endereços para distinguir diferentes protocolos da camada de rede. Para os valores das famílias de endereços, consulte os padrões relevantes.
Armazena a publicidade de informações de roteamento não processada pelo parceiro no BGP speaker local
Segurança BGP
Autenticação BGP
O BGP pode funcionar corretamente somente após o estabelecimento de relacionamentos entre peers do BGP. A autenticação de peers BGP pode melhorar a segurança do BGP. O BGP suporta os seguintes modos de autenticação:
Autenticação MD5
O BGP usa o TCP como o protocolo da camada de transporte. A autenticação Message Digest 5 (MD5) pode ser usada ao estabelecer conexões TCP para melhorar a segurança do BGP. A autenticação MD5 define a senha de autenticação MD5 para a conexão TCP, e o TCP executa a autenticação. Se a autenticação falhar, a conexão TCP não poderá ser estabelecida.
Autenticação Keychain
A autenticação de Keychain é realizada na camada do aplicação. Garante uma transmissão de serviço tranquila e melhora a segurança, alterando periodicamente os algoritmos de senha e criptografia. Quando a autenticação de chaves é configurada para relacionamentos entre pares BGP através de conexões TCP, os pacotes BGP e o processo de estabelecimento de uma conexão TCP podem ser autenticados.
GTSM
Durante ataques de rede, os atacantes podem simular pacotes BGP e enviá-los continuamente ao roteador. Se os pacotes forem destinados ao roteador, ele os encaminha diretamente ao plano de controle para processamento sem validá-los. Como resultado, o aumento da carga de trabalho de processamento no plano de controle resulta em alto uso da CPU.
O GTSM (Generalized TTL Security Mechanism) defende contra ataques, verificando se o valor do tempo de vida (TTL) em cada cabeçalho de pacote IP está dentro de um intervalo predefinido. TTL refere-se ao número máximo de roteadores pelos quais um pacote pode passar.
Os pacotes cujos valores TTL não estão dentro do intervalo especificado podem passar ou serem descartados pelo GTSM. Para configurar o GTSM para descartar pacotes, você precisa definir um intervalo de valores TTL apropriado de acordo com a topologia de rede. Em seguida, os pacotes cujos valores TTL não estão dentro do intervalo especificado são descartados, o que impede o dispositivo local de ataques em potencial.
Você também pode ativar a função de log para gravar pacotes descartados para localização adicional de falhas.
RPKI
A RPKI (Resource Public Key Infrastructure) melhora a segurança do BGP validando os ASs de origem das rotas BGP.
Os invasores podem roubar dados do usuário por rotas de anuncios mais específicas do que as anunciadas pelas operadoras. Por exemplo, se uma operadora tiver anunciado uma rota destinada a 10.10.0.0/16, um invasor poderá anunciar uma rota destinada a 10.10.153.0/16, que é mais específica que 10.10.0.0/16. De acordo com a regra de correspondência mais longa, 10.10.153.0/16 é preferencialmente selecionado para encaminhamento de tráfego. Como resultado, o invasor consegue interceptar os dados do usuário.
Para solucionar esse problema, estabeleça uma sessão RPKI entre um roteador e um servidor RPKI. O roteador consultará as ROAs Route Origin Authorizations (Autorizações de origem de rota) do servidor RPKI através da sessão RPKI e corresponderá à origem AS de cada rota BGP recebida em relação aos ROAs. Esse mecanismo garante que apenas as rotas originadas nos ASs confiáveis sejam aceitas. O resultado da validação também pode ser aplicado à seleção de rota BGP para garantir que os hosts no AS local possam se comunicar com os hosts de outros AS.
Autenticação SSL / TLS
O Secure Sockets Layer (SSL) é um protocolo de segurança que protege a privacidade dos dados na Internet. O Transport Layer Security (TLS) é um sucessor do SSL. O TLS protege a integridade e a privacidade dos dados, impedindo que os invasores interceptem os dados trocados entre um cliente e um servidor. Para garantir a segurança da transmissão de dados em uma rede, a autenticação SSL / TLS pode ser ativada para criptografia de mensagens BGP.

Mensagens BGP

Máquina de estado finito BGP - "Finite State Machine"
O FSM (BGP Finite State Machine) possui seis Estados:

Três estados comuns durante o estabelecimento de relacionamentos entre pares do BGP são: Idle, Active e Established.
No estado inativo Idle, o BGP nega todos os pedidos de conexão. Este é o status inicial do BGP.
No estado Connect, o BGP decide operações subsequentes após o estabelecimento de uma conexão TCP.
No estado Active, o BGP tenta estabelecer uma conexão TCP.
No estado OpenSent, o BGP está aguardando uma mensagem Open do par.
No estado OpenConfirm, o BGP está aguardando uma mensagem de Notificação ou Keepalive.
No estado Established, os pares de BGP podem trocar mensagens de atualização, atualização de rota, manutenção de atividade e notificação.
O relacionamento entre pares do BGP pode ser estabelecido apenas quando os dois pares do BGP estão no estado Established. Ambos os pares enviam mensagens de Update para trocar rotas.
Processamento de rota BGP
O BGP adota o TCP como seu protocolo da camada de transporte. Portanto, uma conexão TCP deve estar disponível entre os pares. Os pares BGP negociam parâmetros trocando mensagens Open para estabelecer um relacionamento entre pares BGP.
Depois que o relacionamento entre pares é estabelecido, os pares BGP trocam as tabelas de roteamento BGP. O BGP não atualiza periodicamente uma tabela de roteamento. Quando as rotas BGP mudam, o BGP atualiza as rotas BGP alteradas na tabela de roteamento BGP enviando mensagens de Update.
O BGP envia mensagens Keepalive para manter a conexão BGP entre pares.
Após detectar um erro em uma rede, o BGP envia uma mensagem de Notification para relatar o erro e a conexão BGP é desativada.
As rotas BGP podem ser importadas de outros protocolos ou aprendidas com os peers. Para reduzir o tamanho do roteamento, você pode configurar o resumo[summarization] da rota após o BGP selecionar as rotas. Além disso, você pode configurar políticas de rota e aplicá-las à importação, recebimento ou anúncio de rota para filtrar rotas ou modificar atributos de rota.
Importação de Rota
O próprio BGP não pode descobrir todas as rotas. Portanto, ele precisa importar outras rotas de protocolo, como rotas IGP ou rotas estáticas, para a tabela de roteamento BGP. As rotas importadas podem ser transmitidas dentro de um AS ou entre ASs.
As rotas BGP são importadas em um dos seguintes modos:
O comando import importa rotas com base nos tipos de protocolo, como rotas RIP, rotas OSPF, rotas IS-IS, rotas estáticas ou rotas diretas.
O comando network importa uma rota com o prefixo e a máscara especificados para a tabela de roteamento BGP, que é mais precisa que o modo anterior.
Interação entre BGP e IGP
• Anuncia as rotas aprendidas dos pares do IBGP apenas para os pares do EBGP
• Anuncia as rotas obtidas dos pares do EBGP para todo o EBGP e IBGP
• Anuncia apenas as melhores rotas BGP para seus pares
• Enviar apenas as rotas BGP atualizadas
• Sincronizar rotas entre IBGP e IGP (usadas no trânsito AS)
Route Summarization
Em uma rede de larga escala, a tabela de roteamento BGP pode ser muito grande. A simarização da rota pode reduzir o tamanho da tabela de roteamento.
A summarização da rota é o processo de resumir rotas específicas com o mesmo prefixo IP em uma rota de resumo. Após o resumo da rota, o BGP anuncia apenas a rota de resumo, em vez de todas as rotas específicas para os pares de BGP.
O BGP suporta o resumo de rotas automático e manual.
Sumarização automática de rotas: entra em vigor nas rotas importadas pelo BGP. Com o Sumarização automáticaa de rotas, as rotas específicas para a Sumarização são suprimidas e o BGP Sumariza as rotas com base no segmento de rede natural e envia apenas a rota par Sumarizada do BGP. Por exemplo, 10.1.1.1/24 e 10.2.1.1/24 estão Sumarizadas em 10.0.0.0/8, que é um endereço de classe A.
Sumarização manual de rotas: entra em vigor nas rotas na tabela de roteamento BGP local. Com o sumarização manual de rotas, os usuários podem controlar os atributos da rota de sumarização e determinar se devem anunciar as rotas específicas.
O IPv4 suporta a sumarização de rotas automático e manual, enquanto o IPv6 suporta apenas o resumo de rotas manual.
Atributos BGP
Os atributos de rota BGP são um conjunto de parâmetros que descrevem rotas BGP específicas. Com os atributos de rota BGP, o BGP pode filtrar e selecionar rotas. Os atributos de rota BGP são classificados nos seguintes tipos:
AS_Sequence: registra na ordem inversa todos os ASs pelos quais uma rota passa do dispositivo local para o destino.
AS_Confed_Set: registra sem ordem todos os sub-ASs em uma confederação BGP através da qual uma rota passa do dispositivo local para o destino. O atributo AS_Confed_Set é usado em cenários de resumo de rota em uma confederação.
Next_Hop
O atributo Next_Hop no BGP não é necessariamente o endereço IP de um roteador vizinho. Na maioria dos casos, o atributo Next_Hop no BGP está em conformidade com as seguintes regras:
MED - Multi-Exit-Discriminator
O Multi-Exit-Discriminator (MED) é transmitido apenas entre dois ASs vizinhos. O AS que recebe o MED não o anuncia para um terceiro AS.
Local_Pref
AIGP - Accumulated Interior Gateway Protocol Metric
Benefícios
Depois que o atributo AIGP é configurado em um domínio administrativo do AIGP, o BGP seleciona caminhos com base nas métricas, assim como um IGP. Consequentemente, todos os dispositivos no domínio administrativo do AIGP usam as rotas ideais para encaminhar dados.
(AS Number : Community Number) - aa:nn: aa indica um número AS e nn indica o identificador da comunidade definido por um administrador.
O primeiro número é o número AS e o segundo número é o número da comunidade.
O valor de aa ou nn varia de 0 a 65535, que é configurável. Por exemplo, se uma rota for do AS 100 e o identificador da comunidade definido pelo administrador for 1, a comunidade será 100: 1.
Quando várias rotas para o mesmo destino estão disponíveis, o BGP seleciona rotas com base nas seguintes regras:
2. Prefere rotas sem erros de bits.
7. Prefere a rota com o menor AS_Path.
O AS_CONFED_SEQUENCE e o AS_CONFED_SET não estão incluídos no AS_Path length
10. Prefere rotas VPN locais, rotas LocalCross e rotas RemoteCross em ordem decrescente.
12. Prefere a rota que se repete para uma rota IGP com o menor custo.
19. Prefere a rota RemoteCross com o menor RD.
20. Prefere rotas recebidas localmente às rotas importadas entre VPN e instâncias de rede pública.
21. Prefere a rota que foi aprendida mais cedo.

Aplicações e Limitações
A confederação precisa ser configurada em cada roteador, e o roteador que ingressa na confederação deve oferecer suporte à função de confederação.
Os speakers BGP precisam ser reconfigurados quando uma rede no modo de non-confederation muda para o modo de confederação. Como resultado, a topologia lógica muda de acordo.
Em redes BGP de grande escala, o RR e a confederação podem ser usados.

BGP GR
O Graceful restart (GR) é uma das tecnologias de alta disponibilidade (HA), que inclui uma série de tecnologias abrangentes, como redundância tolerante a falhas, proteção de link, recuperação de nó com falha e engenharia de tráfego. Como uma tecnologia de redundância tolerante a falhas, o GR garante o encaminhamento normal de dados durante o reinício dos protocolos de roteamento para impedir a interrupção dos principais serviços. Atualmente, o GR tem sido amplamente aplicado à comutação master/slave e atualização do sistema.
O GR geralmente é usado quando o RP (Processador de Rota Ativo) falha devido a um erro de software ou hardware ou usado por um administrador para executar a alternância de master/slave switchover.
Pré-requisito para Implementação
Em um dispositivo de roteamento tradicional, um processador implementa controle e encaminhamento. O processador encontra rotas com base em protocolos de roteamento e mantém a tabela de roteamento e a tabela de encaminhamento do dispositivo. Os dispositivos intermediários e avançados geralmente adotam a estrutura multi-RP para melhorar o desempenho e a confiabilidade do encaminhamento. O processador responsável pelos protocolos de roteamento está localizado na placa de controle principal, enquanto o processador responsável pelo encaminhamento de dados está localizado na placa de interface. O design ajuda a garantir a continuidade do encaminhamento de pacotes na placa de interface durante a reinicialização do processador principal. A tecnologia que separa o controle do encaminhamento atende ao pré-requisito para a implementação do GR.
Atualmente, um dispositivo compatível com GR deve ter duas placas de controle principais. Além disso, a placa de interface deve ter um processador e memória independentes.
Conceitos relacionados
Os conceitos relacionados ao GR são os seguintes:
GR Restarter: indica um dispositivo que realiza a alternância de master/slave acionada pelo administrador ou uma falha. Um GR Restarter deve suportar GR.
GR Helper: indica o vizinho de um GR Restarter. Um auxiliar de GR deve suportar GR.
GR Session: indica uma sessão, através da qual um GR Restarter e um GR Helper podem negociar recursos de GR.
Hora do GR: indica o horário em que o Auxiliar de GR descobre que o GR Restarter está inativo, mas mantém as informações ou rotas da topologia obtidas no GR Restarter.
End-of-RIB (EOR): indica informações de BGP, notificando um BGP de mesmo nível que a primeira atualização de rota é concluída após a negociação.
EOR timer: indica o tempo máximo de um dispositivo local aguardando as informações EOR enviadas do ponto. Se o dispositivo local não receber as informações de EOR do mesmo ponto no temporizador de EOR, o dispositivo local selecionará uma rota ideal das rotas atuais.
Princípios
Os princípios do BGP GR são os seguintes:
Durante o estabelecimento do relacionamento entre peers do BGP, os dispositivos negociam recursos de GR enviando recursos de GR suportados entre si.
Ao detectar a comutação master/slave do GR Restarter, um GR Restarter não exclui as informações de roteamento e encaminhamento de entradas relacionadas ao GR Restarter dentro do tempo de GR, mas aguarda para restabelecer uma conexão BGP com o GR Restarter.
Após a alternância master/slave o GR Restarter recebe rotas de todos os pares negociados com recursos de GR antes da alternância e inicia o temporizador EOR. O GR Restarter seleciona uma rota quando uma das seguintes condições for atendida:
O GR Restarter recebe as informações de EOR de todos os pares e o temporizador de EOR é excluído.
O temporizador EOR atinge o tempo limite, mas o GR Restarter não recebe informações de EOR de todos os pares.
O GR Restarter envia a rota ideal para o GR Helper e o GR Helper inicia o temporizador EOR. O Auxiliar de GR sai do GR quando uma das seguintes condições é atendida:
O GR Helper recebe as informações EOR do GR Restarter e o temporizador EOR é excluído.
O temporizador EOR atinge o tempo limite e o GR Helper não recebe informações EOR do GR Restarter.
GR Reset
Atualmente, o BGP não suporta negociação de capacidade dinâmica. Portanto, sempre que um novo recurso BGP (como os recursos IPv4, IPv6, VPNv4 e VPNv6) é ativado em um speaker BGP, o speaker BGP desativa as sessões existentes com seus pares e renegocia os recursos BGP. Esse processo interromperá os serviços em andamento.
Benefícios
Através do BGP GR, o encaminhamento não é interrompido. Além disso, o bater do BGP ocorre apenas nos vizinhos do GR Restarter e não ocorre em todo o domínio de roteamento. Isso é importante para o BGP que precisa processar um grande número de rotas.
BFD para BGP
O Border Gateway Protocol (BGP) envia periodicamente pacotes Keepalive a um par para monitorar o status do mesmo. No entanto, o BGP leva mais de 1 segundo para a detecção de falhas. Quando o tráfego é transmitido a taxas de gigabit, a detecção prolongada de falhas causa perda de pacotes, o que não atende aos requisitos de rede da operadora para alta confiabilidade.
Bidirectional Forwarding Detection - Detecção de Encaminhamento Bidirecional (BFD) para BGP pode detectar rapidamente falhas no link entre os pares de BGP e notificar o BGP sobre as falhas, o que implementa a convergência rápida da rota BGP.

O BFD está ativado para detectar o relacionamento de ponto EBGP entre o Dispositivo A e o Dispositivo B. Se o link entre o Dispositivo A e o Dispositivo B falhar, o BFD poderá detectar rapidamente a falha e notificar o BGP.
BGP 6PE
À medida que a tecnologia IPv6 se torna mais popular, um número crescente de redes IPv6 separadas toma forma. O IPv6 provider edge (6PE), uma tecnologia projetada para fornecer serviços IPv6 em redes IPv4, permite que os provedores de serviços forneçam serviços IPv6 sem construir redes de backbone IPv6. A solução 6PE conecta redes IPv6 separadas usando túneis MPLS (Multiprotocol Label Switching). A solução 6PE implementa a pilha dupla IPv4 / IPv6 nos dispositivos de borda do provedor (PEs) dos provedores de serviços da Internet e usa as extensões multiprotocolo para o protocolo Border Gateway (MP-BGP) para atribuir rótulos às rotas IPv6. Dessa maneira, a solução 6PE conecta redes IPv6 separadas por túneis IPv4 entre PEs.
Conceitos relacionados
Na aplicação prática, diferentes redes de área metropolitana (MANs) de um provedor de serviços ou redes de backbone colaborativas de diferentes provedores de serviços geralmente abrangem vários sistemas autônomos (AS).
A solução 6PE pode ser intra-AS 6PE ou inter-AS 6PE, dependendo se redes IPv6 separadas se conectam ao mesmo AS. O protocolo padrão fornece três modos inter-AS 6PE: inter-AS 6PE OptionB, inter-AS 6PE OptionB com roteadores de limite de sistema autônomo (ASBRs) como PEs e inter-AS OptionC. Esta seção descreve os seguintes modos 6PE:
Intra-AS 6PE: redes IPv6 separadas são conectadas pelo mesmo AS. Os PEs no AS trocam rotas IPv6 estabelecendo relacionamentos entre pares MP-IBGP.
Inter-AS 6PE OptionB: ASBRs em ASs diferentes trocam rotas IPv6 rotuladas estabelecendo relacionamentos de pares MP-EBGP.
Inter-AS 6PE OptionB (com ASBRs como PEs): ASBRs em diferentes ASs trocam rotas IPv6 usando MP-EBGP.
Inter-AS 6PE OptionC: PEs em ASs diferentes trocam rotas IPv6 rotuladas em sessões MP-EBGP de vários hop.
ORG BGP
Outbound Route Filtering - A Filtragem de rota de saída (ORF) é usada para permitir que um dispositivo BGP envie a política de roteamento local para seu par BGP. O par pode usar a política de roteamento local para filtrar rotas indesejadas antes do anúncio da rota.
Na maioria dos casos, os usuários esperam que a operadora envie apenas as rotas necessárias. Portanto, a operadora precisa manter uma política de saída separada para cada usuário. O ORF permite que as transportadoras enviem apenas rotas necessárias para cada usuário sem manter uma política de saída separada para cada usuário. O ORF suporta anúncios de rotas sob demanda, o que reduz bastante o consumo de largura de banda e a carga de trabalho de configuração manual.
O ORF baseado em prefixo, definido em protocolos padrão, pode ser usado para enviar políticas de entrada baseadas em prefixo configuradas pelos usuários a uma operadora por meio de pacotes de atualização de rota. A transportadora filtra as rotas indesejadas antes do anúncio de rotas com base nas políticas de entrada recebidas, o que impede que os usuários recebam um grande número de rotas indesejadas e economiza recursos.
- O BGP é amplamente usado pelos ISPs (Internet Service Providers).
- O Border Gateway Protocol (BGP) é um protocolo do tipo distance-vector.
- O BGP usa o Transport Control Protocol (TCP) como o protocolo da camada de transporte, o que aprimora a confiabilidade do BGP.
- O BGP suporta CIDR (Roteamento entre domínios sem classe).
- Os pares BGP devem ser conectados logicamente através do TCP. O número da porta de destino é 179 e o número da porta local é um valor aleatório.
- O BGP seleciona rotas inter-AS, o que impõe altos requisitos de estabilidade. Portanto, o uso do TCP aprimora a estabilidade do BGP.
- Quando as rotas são atualizadas, o BGP transmite apenas as rotas atualizadas, o que reduz o consumo de largura de banda durante a distribuição de rotas do BGP. Portanto, o BGP é aplicável à Internet, onde um grande número de rotas é transmitido.
- O BGP foi projetado para evitar loops:
- Entre ASs: As rotas BGP carregam informações sobre os ASs ao longo do caminho. As rotas que levam o número AS local são descartadas para evitar loops entre AS
- O BGP garante alta segurança, flexibilidade, estabilidade, confiabilidade e eficiência da rede:O BGP usa autenticação e GTSM (Generalized TTL Security Mechanism) para garantir a segurança da rede.O BGP fornece políticas de roteamento para permitir a seleção de rotas flexível.O BGP fornece o resumo da rota e o sumarização da rota para evitar oscilações e assim e melhorar a estabilidade da rede.
Definição de
BGP4 +
Como
um protocolo de roteamento dinâmico usado entre ASs, o BGP4 + é uma extensão do
BGP.
O
BGP4 tradicional gerencia as informações de roteamento IPv4, mas não suporta a
transmissão inter-AS de pacotes encapsulados por outros protocolos da camada de
rede (como o IPv6).
Para
oferecer suporte ao IPv6, o BGP4 deve ter a capacidade adicional de associar um
protocolo IPv6 às informações do próximo salto e às informações acessíveis na
camada de rede (NLRI).
Dois
atributos NLRI que foram introduzidos no BGP4 + são os seguintes:
Multiprotocol Reachable NLRI - (MP_REACH_NLRI):
transporta o conjunto de destinos alcançáveis e as informações do próximo
salto usadas para o encaminhamento de pacotes.
Multiprotocol Unreachable NLRI - (MP_UNREACH_NLRI): carrega o
conjunto de destinos inacessíveis.
O atributo Next_Hop no BGP4 + está
no formato de um endereço IPv6, que pode ser um endereço IPv6 globalmente
exclusivo ou um endereço local do link do próximo salto.
O BGP-4 convencional gerencia apenas as informações de roteamento unicast IPv4 e a transmissão inter-AS de pacotes de outros protocolos da camada de rede, como o multicast, é limitada.
Para oferecer suporte a vários protocolos da camada de rede, a Internet Engineering Task Force (IETF) estende o BGP-4 às extensões de multiprotocolo para BGP-4 (MP-BGP). MP-BGP é compatível com a frente. Especificamente, os roteadores que suportam MP-BGP podem se comunicar com os roteadores que não suportam MP-BGP.
Como um aprimoramento do BGP-4, o MP-BGP fornece informações de roteamento para vários protocolos de roteamento, incluindo IPv6 (BGP-4) e multicast.
O MP-BGP mantém rotas unicast e multicast. Ele as armazena em diferentes tabelas de roteamento para separar as informações de roteamento unicast das informações de roteamento multicast.
O MP-BGP suporta famílias de endereços unicast e multicast e pode construir a topologia de roteamento unicast e a topologia de roteamento multicast.
A maioria das políticas e configurações de roteamento unicast suportadas pelo BGP-4 pode ser aplicada ao multicast e o BGP-4 pode manter rotas unicast e multicast de acordo com essas políticas de roteamento.
Família de endereços
O campo Informações da família de endereços consiste em um AFI (identificador da família de endereços) de 2 bytes e um SAFI (identificador da família de endereços subseqüente) de 1 byte.
O BGP usa famílias de endereços para distinguir diferentes protocolos da camada de rede. Para os valores das famílias de endereços, consulte os padrões relevantes.
Databases BGP
IP-RIB - Tabela de roteamento IP
Base global de informações de roteamento, que armazena todas as informações de roteamento IP
LOC-RIB - Tabela de roteamento BGP
Armazena as informações de roteamento local que o BGP Speaker local selecionou
Banco de dados de pares BGP
Lista de peers BGP
ADJ-RIB-In
Armazena a publicidade de informações de roteamento não processada pelo parceiro no BGP speaker local
ADJ-RIB-out
Armazena as informações de roteamento anunciadas pelo alto-falante BGP em um ponto especificado
Autenticação BGP
O BGP pode funcionar corretamente somente após o estabelecimento de relacionamentos entre peers do BGP. A autenticação de peers BGP pode melhorar a segurança do BGP. O BGP suporta os seguintes modos de autenticação:
Autenticação MD5
O BGP usa o TCP como o protocolo da camada de transporte. A autenticação Message Digest 5 (MD5) pode ser usada ao estabelecer conexões TCP para melhorar a segurança do BGP. A autenticação MD5 define a senha de autenticação MD5 para a conexão TCP, e o TCP executa a autenticação. Se a autenticação falhar, a conexão TCP não poderá ser estabelecida.
Autenticação Keychain
A autenticação de Keychain é realizada na camada do aplicação. Garante uma transmissão de serviço tranquila e melhora a segurança, alterando periodicamente os algoritmos de senha e criptografia. Quando a autenticação de chaves é configurada para relacionamentos entre pares BGP através de conexões TCP, os pacotes BGP e o processo de estabelecimento de uma conexão TCP podem ser autenticados.
GTSM
Durante ataques de rede, os atacantes podem simular pacotes BGP e enviá-los continuamente ao roteador. Se os pacotes forem destinados ao roteador, ele os encaminha diretamente ao plano de controle para processamento sem validá-los. Como resultado, o aumento da carga de trabalho de processamento no plano de controle resulta em alto uso da CPU.
O GTSM (Generalized TTL Security Mechanism) defende contra ataques, verificando se o valor do tempo de vida (TTL) em cada cabeçalho de pacote IP está dentro de um intervalo predefinido. TTL refere-se ao número máximo de roteadores pelos quais um pacote pode passar.
Os pacotes cujos valores TTL não estão dentro do intervalo especificado podem passar ou serem descartados pelo GTSM. Para configurar o GTSM para descartar pacotes, você precisa definir um intervalo de valores TTL apropriado de acordo com a topologia de rede. Em seguida, os pacotes cujos valores TTL não estão dentro do intervalo especificado são descartados, o que impede o dispositivo local de ataques em potencial.
Você também pode ativar a função de log para gravar pacotes descartados para localização adicional de falhas.
RPKI
A RPKI (Resource Public Key Infrastructure) melhora a segurança do BGP validando os ASs de origem das rotas BGP.
Os invasores podem roubar dados do usuário por rotas de anuncios mais específicas do que as anunciadas pelas operadoras. Por exemplo, se uma operadora tiver anunciado uma rota destinada a 10.10.0.0/16, um invasor poderá anunciar uma rota destinada a 10.10.153.0/16, que é mais específica que 10.10.0.0/16. De acordo com a regra de correspondência mais longa, 10.10.153.0/16 é preferencialmente selecionado para encaminhamento de tráfego. Como resultado, o invasor consegue interceptar os dados do usuário.
Para solucionar esse problema, estabeleça uma sessão RPKI entre um roteador e um servidor RPKI. O roteador consultará as ROAs Route Origin Authorizations (Autorizações de origem de rota) do servidor RPKI através da sessão RPKI e corresponderá à origem AS de cada rota BGP recebida em relação aos ROAs. Esse mecanismo garante que apenas as rotas originadas nos ASs confiáveis sejam aceitas. O resultado da validação também pode ser aplicado à seleção de rota BGP para garantir que os hosts no AS local possam se comunicar com os hosts de outros AS.
Autenticação SSL / TLS
O Secure Sockets Layer (SSL) é um protocolo de segurança que protege a privacidade dos dados na Internet. O Transport Layer Security (TLS) é um sucessor do SSL. O TLS protege a integridade e a privacidade dos dados, impedindo que os invasores interceptem os dados trocados entre um cliente e um servidor. Para garantir a segurança da transmissão de dados em uma rede, a autenticação SSL / TLS pode ser ativada para criptografia de mensagens BGP.
Objetivo do BGP:
O BGP transmite informações de rota entre os ASs. No entanto, não é necessário em todos os cenários.
O BGP é necessário nos seguintes cenários:
Na rede mostrada acima, os usuários precisam estar conectados a dois ou mais ISPs. Os ISPs precisam fornecer todas ou parte das rotas da Internet para os usuários. Portanto, os roteadores precisam selecionar a rota ideal através do AS de um ISP para o destino com base nos atributos transportados nas rotas BGP.
O atributo AS_Path precisa ser transmitido entre usuários em diferentes organizações.
Os usuários precisam transmitir rotas multicast e construir uma topologia multicast.
O BGP não é necessário nos seguintes cenários:
Os usuários estão conectados a apenas um ISP.
O ISP não precisa fornecer rotas da Internet para os usuários.
Os ASs são conectados através de rotas padrão.
Funções na transmissão de
mensagens BGP
Speaker: Qualquer
roteador que envia mensagens BGP é chamado de speaker BGP. O speaker recebe ou gera novas informações de roteamento e, em seguida, anuncia as
informações de roteamento para outros speaker do BGP. Depois de receber
uma rota de outro AS, um speaker BGP compara a rota com suas rotas locais.
Se a rota for melhor do que suas rotas locais, ou a rota nova, o speaker anuncia essa rota para todos os outros speakers do BGP.
Peer: Os speakers de BGP que trocam mensagens entre si são chamados de peers.
Mensagens BGP
O BGP é executado enviando cinco tipos de mensagens:
·
Open
·
Update
·
Notification
·
Keepalive
·
Route-refresh
Open: É a primeira mensagem enviada após a configuração de uma conexão TCP é uma mensagem open, usada para configurar relacionamentos entre peers do BGP. Depois que um par recebe uma mensagem open e a negociação é bem-sucedida, ele envia uma mensagem Keepalive para confirmar e manter o relacionamento. Em seguida, os peers podem trocar mensagens de Update, Notification, Keepalive e Route-refresh messages.
Update: Este tipo de mensagem é usada para trocar rotas entre pares BGP.
Uma mensagem de atualização pode anunciar várias rotas alcançáveis com os mesmos atributos. Esses atributos de rota são aplicáveis a todos os endereços de destino (expressos por prefixos IP) no campo NLRI (Network Layer Reachability Information) da mensagem Update.
Uma mensagem de Update pode ser usada para excluir várias rotas inacessíveis. Cada rota é identificada pelo seu endereço de destino (usando o prefixo IP), que identifica as rotas anunciadas anteriormente entre os alto-falantes do BGP.
Uma mensagem de Update pode ser usada apenas para excluir rotas. Nesse caso, ele não precisa carregar os atributos de rota ou NLRI. Além disso, uma mensagem de atualização pode ser usada apenas para anunciar rotas acessíveis. Nesse caso, ele não precisa levar informações sobre as rotas excluídas.
Notification: Quando o BGP detecta um erro, envia uma mensagem de Notification ao seu par. A conexão BGP é então interrompida imediatamente.
Keepalive: o BGP envia periodicamente mensagens de Keepalive aos pares para manter relacionamentos entre pares.
Route-refresh: Esse tipo de mensagem é usada para solicitar que o par reenvie todas as rotas acessíveis.
Se todos os roteadores BGP estiverem habilitados com o recurso de atualização de rota e a política de importação do BGP for alterada, o roteador BGP local envia uma mensagem de atualização de rota para seus pares. Após receber a mensagem de atualização de rota, os pares reenviam suas informações de roteamento para o roteador BGP local. Dessa maneira, as tabelas de roteamento BGP são atualizadas dinamicamente e novas políticas de roteamento são usadas sem derrubar as conexões BGP.
BGP Neighbor Adjacency States
O FSM (BGP Finite State Machine) possui seis Estados:
·
Idle
·
Connect
·
Active
·
OpenSent
·
OpenConfirm
·
Established
Três estados comuns durante o estabelecimento de relacionamentos entre pares do BGP são: Idle, Active e Established.
No estado inativo Idle, o BGP nega todos os pedidos de conexão. Este é o status inicial do BGP.
No estado Connect, o BGP decide operações subsequentes após o estabelecimento de uma conexão TCP.
No estado Active, o BGP tenta estabelecer uma conexão TCP.
No estado OpenSent, o BGP está aguardando uma mensagem Open do par.
No estado OpenConfirm, o BGP está aguardando uma mensagem de Notificação ou Keepalive.
No estado Established, os pares de BGP podem trocar mensagens de atualização, atualização de rota, manutenção de atividade e notificação.
O relacionamento entre pares do BGP pode ser estabelecido apenas quando os dois pares do BGP estão no estado Established. Ambos os pares enviam mensagens de Update para trocar rotas.
Processamento de rota BGP
O BGP adota o TCP como seu protocolo da camada de transporte. Portanto, uma conexão TCP deve estar disponível entre os pares. Os pares BGP negociam parâmetros trocando mensagens Open para estabelecer um relacionamento entre pares BGP.
Depois que o relacionamento entre pares é estabelecido, os pares BGP trocam as tabelas de roteamento BGP. O BGP não atualiza periodicamente uma tabela de roteamento. Quando as rotas BGP mudam, o BGP atualiza as rotas BGP alteradas na tabela de roteamento BGP enviando mensagens de Update.
O BGP envia mensagens Keepalive para manter a conexão BGP entre pares.
Após detectar um erro em uma rede, o BGP envia uma mensagem de Notification para relatar o erro e a conexão BGP é desativada.
As rotas BGP podem ser importadas de outros protocolos ou aprendidas com os peers. Para reduzir o tamanho do roteamento, você pode configurar o resumo[summarization] da rota após o BGP selecionar as rotas. Além disso, você pode configurar políticas de rota e aplicá-las à importação, recebimento ou anúncio de rota para filtrar rotas ou modificar atributos de rota.
Importação de Rota
O próprio BGP não pode descobrir todas as rotas. Portanto, ele precisa importar outras rotas de protocolo, como rotas IGP ou rotas estáticas, para a tabela de roteamento BGP. As rotas importadas podem ser transmitidas dentro de um AS ou entre ASs.
As rotas BGP são importadas em um dos seguintes modos:
O comando import importa rotas com base nos tipos de protocolo, como rotas RIP, rotas OSPF, rotas IS-IS, rotas estáticas ou rotas diretas.
O comando network importa uma rota com o prefixo e a máscara especificados para a tabela de roteamento BGP, que é mais precisa que o modo anterior.
Interação entre BGP e IGP
• Anuncia as rotas aprendidas dos pares do IBGP apenas para os pares do EBGP
• Anuncia as rotas obtidas dos pares do EBGP para todo o EBGP e IBGP
• Anuncia apenas as melhores rotas BGP para seus pares
• Enviar apenas as rotas BGP atualizadas
• Sincronizar rotas entre IBGP e IGP (usadas no trânsito AS)
Route Summarization
Em uma rede de larga escala, a tabela de roteamento BGP pode ser muito grande. A simarização da rota pode reduzir o tamanho da tabela de roteamento.
A summarização da rota é o processo de resumir rotas específicas com o mesmo prefixo IP em uma rota de resumo. Após o resumo da rota, o BGP anuncia apenas a rota de resumo, em vez de todas as rotas específicas para os pares de BGP.
O BGP suporta o resumo de rotas automático e manual.
Sumarização automática de rotas: entra em vigor nas rotas importadas pelo BGP. Com o Sumarização automáticaa de rotas, as rotas específicas para a Sumarização são suprimidas e o BGP Sumariza as rotas com base no segmento de rede natural e envia apenas a rota par Sumarizada do BGP. Por exemplo, 10.1.1.1/24 e 10.2.1.1/24 estão Sumarizadas em 10.0.0.0/8, que é um endereço de classe A.
Sumarização manual de rotas: entra em vigor nas rotas na tabela de roteamento BGP local. Com o sumarização manual de rotas, os usuários podem controlar os atributos da rota de sumarização e determinar se devem anunciar as rotas específicas.
O IPv4 suporta a sumarização de rotas automático e manual, enquanto o IPv6 suporta apenas o resumo de rotas manual.
Atributos BGP
Os atributos de rota BGP são um conjunto de parâmetros que descrevem rotas BGP específicas. Com os atributos de rota BGP, o BGP pode filtrar e selecionar rotas. Os atributos de rota BGP são classificados nos seguintes tipos:
Well-known mandatory: Este tipo de atributo pode ser identificado por todos os roteadores BGP e deve ser carregado nas mensagens de atualização. Sem esse atributo, ocorrem erros nas informações de roteamento.
Well-known discretionary: Este tipo de atributo pode ser identificado por todos os roteadores BGP. Esse tipo de atributo é opcional e, portanto, não é necessariamente carregado nas mensagens de atualização.
Optional transitive: Indica o atributo transitivo entre os ASs. Um roteador BGP pode não reconhecer esse atributo, mas o roteador ainda o recebe e o anuncia a outros pares.
Optional non-transitive: Se um roteador BGP não reconhecer esse tipo de atributo, o roteador não o anunciará para outros pares.
Os atributos de rota BGP mais comuns são os seguintes:
Origin
O atributo Origin define a origem de uma rota. O atributo Origem é classificado nos seguintes tipos:
Protocolo de Gateway Interior (IGP) (I): este tipo de atributo tem a maior prioridade. IGP é o atributo Origin para rotas obtidas por meio de um IGP no AS do qual as rotas se originam. Por exemplo, o atributo Origem das rotas importadas para a tabela de roteamento BGP usando o comando network é IGP.
• Uma rota deste tipo é definida com um “I” na tabela BGP
• Uma rota deste tipo é definida com um “I” na tabela BGP
Protocolo de gateway externo (EGP) (E): esse tipo de atributo tem a segunda maior prioridade. O atributo Origin das rotas obtidas através do EGP é EGP.
• Uma rota desse tipo é identificada com um “E” na tabela BGP
• Uma rota desse tipo é identificada com um “E” na tabela BGP
Incompleto (?): esse tipo de atributo tem a menor prioridade. Incompleto é o tipo de atributo Origem de todas as rotas que não possuem o atributo IGP ou EGP Origin. Por exemplo, o atributo Origem das rotas importadas usando o comando import-route é Incompleto.
• Uma rota deste tipo é definida com na "?" na tabela BGP.
• Uma rota deste tipo é definida com na "?" na tabela BGP.
AS_Path
O atributo AS-Path registra todos os ASs pelos quais uma rota passa da extremidade local para o destino na ordem do vetor de distância (DV).
Ao anunciar a rota além do AS local, o speaker do BGP adiciona o número do AS local à lista AS_Path e o anuncia aos roteadores vizinhos por meio de mensagens de update.
Ao anunciar a rota no AS local, o speaker do BGP cria uma lista vazia do AS_Path em uma mensagem de Update.
Quando um speaker do BGP anuncia uma rota aprendida nas mensagens de atualização de outro speaker do BGP:
Ao anunciar a rota além do AS local, o speaker do BGP adiciona o número do AS local à esquerda da lista do AS_Path. No atributo AS_Path, o roteador BGP que recebe a rota aprende os ASs pelos quais a rota passa para o destino. O número do AS mais próximo do AS local é colocado à esquerda da lista, enquanto outros números do AS são listados em sequência.
Ao anunciar a rota no AS local, o speaker do BGP não altera o atributo AS_Path.
O atributo AS_Path possui quatro tipos:
AS_Sequence: registra na ordem inversa todos os ASs pelos quais uma rota passa do dispositivo local para o destino.
AS_Set: registra sem um pedido todos os ASs pelos quais uma rota passa do dispositivo local para o destino. O atributo AS_Set é usado em cenários de resumo de rotas. Após o resumo da rota, o dispositivo registra os números de AS não sequenciais porque não pode sequenciar os números de ASs pelos quais passam rotas específicas. Não importa quantos números AS um AS_Set contenha, o BGP considera o AS_Set como um número AS ao calcular rotas.
AS_Confed_Sequence: registra em ordem inversa todos os sub-ASs dentro de uma confederação BGP através da qual uma rota passa do dispositivo local para o destino.
AS_Confed_Set: registra sem ordem todos os sub-ASs em uma confederação BGP através da qual uma rota passa do dispositivo local para o destino. O atributo AS_Confed_Set é usado em cenários de resumo de rota em uma confederação.
Os atributos AS_Confed_Sequence e AS_Confed_Set são usados para evitar loops de roteamento e para selecionar rotas entre os vários sub-ASs em uma Confederation.
Next_Hop
O atributo Next_Hop no BGP não é necessariamente o endereço IP de um roteador vizinho. Na maioria dos casos, o atributo Next_Hop no BGP está em conformidade com as seguintes regras:
Ao anunciar uma rota para um ponto EBGP, um speaker do BGP define o Next_Hop da rota como o endereço da interface local através da qual o relacionamento do ponto BGP é estabelecido.
Ao anunciar uma rota gerada localmente para um par IBGP, um speaker do BGP define o Next_Hop da rota como o endereço da interface local através da qual o relacionamento entre peers BGP é estabelecido.
Ao anunciar uma rota aprendida de um ponto EBGP para um ponto IBGP, o orador do BGP não altera o Next_Hop da rota.
MED - Multi-Exit-Discriminator
O Multi-Exit-Discriminator (MED) é transmitido apenas entre dois ASs vizinhos. O AS que recebe o MED não o anuncia para um terceiro AS.
Semelhante ao custo usado por um IGP, o MED é usado para determinar a rota ideal quando o tráfego entra no AS. Quando um par BGP aprende várias rotas que têm o mesmo endereço de destino, mas diferentes saltos seguintes dos pares EBGP, a rota com o menor valor MED é selecionada como a rota ideal, se todos os outros atributos forem iguais.
Local_Pref
O atributo Local_Pref indica a prioridade BGP de uma rota. Está disponível apenas para pares do IBGP e não é anunciado para outros ASs.
O atributo Local_Pref é usado para determinar a rota ideal quando o tráfego sai de um AS. Quando um roteador BGP obtém várias rotas para o mesmo endereço de destino, mas com próximos saltos diferentes por meio de pares IBGP, a rota com o maior valor Local_Pref é selecionada.
AIGP - Accumulated Interior Gateway Protocol Metric
O atributo AIGP (Accumulated Interior Gateway Protocol Metric) é um atributo de caminho opcional não transitivo do Border Gateway Protocol (BGP). O código do tipo de atributo atribuído pela IANA (Internet Assigned Numbers Authority) para o atributo AIGP é 26.
Protocolos de roteamento, como IGPs que foram projetados para serem executados em um único domínio administrativo, geralmente atribuem uma métrica a cada link e, em seguida, escolhem o caminho com a menor métrica como o caminho ideal entre dois nós. O BGP, projetado para fornecer roteamento em um grande número de domínios administrativos independentes, não seleciona caminhos com base em métricas. Se um único domínio administrativo executar várias redes BGP contíguas, é desejável que o BGP selecione caminhos com base em métricas, assim como um IGP. O atributo AIGP permite ao BGP selecionar caminhos com base em métricas.
Um domínio administrativo do AIGP é um conjunto de sistemas autônomos (AS) em um domínio administrativo comum. O atributo AIGP entra em vigor apenas em um domínio administrativo AIGP
Origem do Atributo AIGP
O atributo AIGP pode ser adicionado a uma rota apenas através de uma política de rota. Você pode configurar uma rota BGP para adicionar um valor AIGP quando as rotas são importadas, recebidas ou enviadas. Se nenhum valor AIGP estiver configurado, as rotas BGP não conterão atributos AIGP
O atributo AIGP é usado para selecionar a rota ideal em um domínio administrativo do AIGP.
O atributo AIGP pode ser transmitido entre pares unicast BGP, bem como entre pares Bvp VPNv4 / VPNv6. A transmissão do atributo AIGP entre os pares BGP VPNv4 / VPNv6 permite que o tráfego L3VPN seja transmitido ao longo do caminho com o menor valor de atributo AIGP.
Benefícios
Depois que o atributo AIGP é configurado em um domínio administrativo do AIGP, o BGP seleciona caminhos com base nas métricas, assim como um IGP. Consequentemente, todos os dispositivos no domínio administrativo do AIGP usam as rotas ideais para encaminhar dados.
Community Attribute
O atributo Community BGP é um atributo BGP Optional Transitive
Com o atributo Community os destinos são agrupados e as decisões de política de rota do BGP são feitas de maneira especial para cada uma dessas comunidades. Os atributos da comunidade BGP são atribuídos a prefixos específicos e anunciados aos vizinhos.
O vizinho que recebe esses anúncios reconhece esse valor e se comporta de acordo com este atributo da comunidade. (Anuncie novamente ou não).
Com o BGP Community Attribute, podemos aplicar políticas especiais a clientes especiais. Esse tipo de configuração oferece aos clientes fácil gerenciamento de suas rotas BGP de forma independente.
O atributo community é um grupo de endereços de destino com as mesmas características e consiste em um conjunto de valores de 4 bytes que especificam uma comunidade. O atributo da comunidade é expresso no formato aa: nn ou como um número da comunidade.
(AS Number : Community Number) - aa:nn: aa indica um número AS e nn indica o identificador da comunidade definido por um administrador.
O primeiro número é o número AS e o segundo número é o número da comunidade.
O valor de aa ou nn varia de 0 a 65535, que é configurável. Por exemplo, se uma rota for do AS 100 e o identificador da comunidade definido pelo administrador for 1, a comunidade será 100: 1.
Número da comunidade: é um número inteiro que varia de 0 a 4294967295. Conforme definido nos protocolos padrão, os números de 0 (0x00000000) a 65535 (0x0000FFFF) e de 4294901760 (0xFFFF0000) a 4294967295 (0xFFFFFFFF) são reservados.
Com o atributo community, um grupo de peers BGP em vários ASs pode compartilhar a mesma política de roteamento. O atributo community é um atributo de rota. É transmitido entre peers BGP e não é restrito pelo AS. Antes de anunciar uma rota com o atributo de comunidade para peers, um par de BGP pode alterar o atributo de comunidade original dessa rota.
Os peers em um grupo de peers compartilham a mesma política, enquanto as rotas com o mesmo atributo de comunidade compartilham a mesma política.
As comunidades conhecidas são descritas na próxima seção. Os usuários também podem criar suas próprias comunidades para filtrar rotas.
O BGP possui quatro comunidades Well-known
communities que podem ser usadas para marcar prefixos; listados da seguinte forma:
Internet: anuncie essas rotas a todos os vizinhos.
Local-as: impede o envio de rotas fora do local como dentro da confederação.
Informa aos vizinhos do BGP que devem anunciar um prefixo apenas para os vizinhos do iBGP.
Este atributo impede o anuncio das rotas para afastar o Sistema Autônomo Local (AS) ou outros pares da Confederação. É semelhante a no-export, exceto um ponto. Com essa Well Known community, você pode anunciar as rotas apenas para os roteadores na mesma Confederação BGP.
Em outras palavras, você pode anunciar rotas dentro do mesmo sub-AS da Confederação, não pode anunciar as rotas para o outro sub-AS da Confederação.
No-Advertise: não anuncie esta rota a nenhum peer, interno ou externo.
No-Advertise Community impede o anuncio das rotas para qualquer par, interno ou externo. Portanto, o roteador que obtém esse tipo de rota, o armazena apenas e não o envia a nenhum vizinho iBGP ou eBGP.
No-Export: não anuncie esta rota para peers externos do BGP.
Esta atributo previne o anuncio de rotas para fora do sistema local de autônomos. As rotas que vêm com esse atributo não são anunciadas aos peers do eBGP. Assim, você pode anunciar rotas para os vizinhos iBGP com essas Well Known BGP Communities. Com BGP No-Export Community, impedimos que nosso sistema autônomo também se torne um AS de trânsito.
Seleção de rota BGP
Quando várias rotas para o mesmo destino estão disponíveis, o BGP seleciona rotas com base nas seguintes regras:
1. Prefere rotas na ordem decrescente de Estados de validação AS válidos, Não encontrados e Inválidos após a origem BGP AS são aplicados à seleção de rota em um cenário em que o dispositivo está conectado a um servidor RPKI.
2. Prefere rotas sem erros de bits.
Se o comando bestroute bit-error-detection for executado, o BGP selecionará preferencialmente rotas sem eventos de erro de bit.
3. Prefere a rota com o maior valor de PreVal.
PrefVal é específico da Huawei. É válido apenas no dispositivo em que está configurado.
4. Prefere a rota com o maior valor Local_Pref.
Se uma rota não levar Local_Pref, o valor padrão 100 entrará em vigor. Para alterar o valor, execute o comando default local-preference
5. Prefere uma rota de origem local a uma rota aprendida de um par.
As rotas de origem local incluem rotas importadas usando o comando network ou import-route, bem como rotas de resumo manual e automaticamente.
a. Prefere uma rota sumarizada em vez de uma rota não sumarizada
b. Prefere uma rota obtida usando o comando aggregate sobre uma rota obtida usando o comando summary automatic
c. Prefere uma rota importada usando o comando network sobre uma rota importada usando o comando import-route.
6. Prefere uma rota que carrega o atributo AIGP (Accumulated Interior Gateway Protocol Metric).
A prioridade de uma rota que transporta o atributo AIGP é maior que a prioridade de uma rota que não transporta o atributo AIGP.
Se duas rotas carregam o atributo AIGP, a rota com um valor menor do atributo AIGP mais a métrica IGP do próximo salto recursivo é preferível à outra rota.
7. Prefere a rota com o menor AS_Path.
O AS_CONFED_SEQUENCE e o AS_CONFED_SET não estão incluídos no AS_Path length
Durante a seleção de rota, um roteador assume que um AS_SET carrega apenas um número de AS, independentemente do número real de ASs.
Se o comando bestroute as-path-ignore for executado, o BGP não compara mais o atributo AS_Path.
8. Prefere a rota com o tipo de Origem como IGP, EGP e Incomplete em ordem decrescente.
9. Prefere a rota com o menor valor MED.
] O BGP compara os MEDs apenas de rotas do mesmo AS (excluindo sub-ASs da confederação). Os MEDs de duas rotas são comparados apenas quando o primeiro número AS no AS_Sequence (excluindo AS_Confed_Sequence) de uma rota é igual ao seu equivalente na outra rota.
Se uma rota não possuir MED, o BGP considerará sua MED como o valor padrão (0) durante a seleção da rota. Se o comando bestroute med-none-as-maximum for executado, o BGP considerará seu MED como o maior valor MED (4294967295).
Se o comando compare-different-as-med for executado, o BGP compara MEDs de rotas mesmo quando as rotas são recebidas de pares em diferentes ASs. Não execute este comando, a menos que os ASs usem o mesmo IGP e modo de seleção de rota. Caso contrário, um loop pode ocorrer.
Se o comando deterministic-med for executado, as rotas não serão mais selecionadas na sequência em que são recebidas.
10. Prefere rotas VPN locais, rotas LocalCross e rotas RemoteCross em ordem decrescente.
• Se o ERT de uma rota VPNv4 na tabela de roteamento de uma instância VPN em um PE corresponder ao IRT de outra instância VPN no PE, a rota VPNv4 será adicionada à tabela de roteamento da segunda instância VPN. Essa rota é chamada de rota LocalCross. Se o ERT de uma rota VPNv4 aprendida em um PE remoto corresponder ao IRT de uma instância VPN no PE local, a rota VPNv4 será adicionada à tabela de roteamento dessa instância VPN. Essa rota é chamada de rota RemoteCross.
11. Prefere rotas EBGP para rotas IBGP.
12. Prefere a rota que se repete para uma rota IGP com o menor custo.
Se o comando bestroute igp-metric-ignore for executado, o BGP não compara mais o custo do IGP.
13. Prefere a rota com a menor Cluster_List.
14. Prefere a rota anunciada pelo roteador com o menor ID do roteador.
Se o comando bestroute router-id-ignore for executado, os IDs do roteador não determinam qual rota será selecionada para o BGP.
15. Prefere a rota aprendida do par com o menor endereço IP.
16. Se as rotas de especificação de fluxo BGP forem configuradas localmente, a primeira rota de especificação de fluxo BGP configurada é preferencialmente selecionada.
17. Prefere a rota importada localmente na tabela de roteamento RM.
• Se uma rota direta, rota estática e rota IGP forem importadas, o BGP selecionará preferencialmente a rota direta, rota estática e rota IGP em ordem decrescente.
18. Prefere a rota Add-Path com o menor ID de caminho de recv.
19. Prefere a rota RemoteCross com o menor RD.
20. Prefere rotas recebidas localmente às rotas importadas entre VPN e instâncias de rede pública.
21. Prefere a rota que foi aprendida mais cedo.
PEER Group
Um grupo de pares é um conjunto de pares com as mesmas políticas. Quando um par se junta a um grupo de pares, ele herda as configurações do grupo de pares. Se as configurações do grupo de pares forem alteradas, as configurações de todos os pares do grupo serão alteradas de acordo.
Em uma rede BGP de larga escala, existem muitos pares e a maioria deles precisa das mesmas políticas. Portanto, alguns comandos precisam ser executados repetidamente em cada par. A configuração de um grupo de pares pode simplificar a configuração.
Cada par em um grupo de pares pode ser configurado com políticas exclusivas para anunciar e receber rotas.
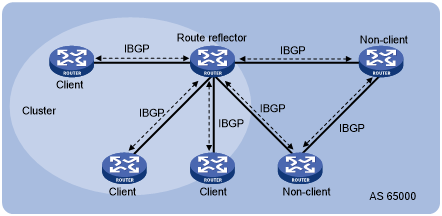
Route Reflector
Para garantir a conectividade entre os pares do IBGP, é necessário estabelecer conexões de full-mesh completa entre os pares do IBGP. Se houver n dispositivos em um AS, é necessário estabelecer conexões entre todos os roteadores IBGP.
Funções no Route-Reflector
Refletor de rota (RR): um dispositivo BGP que pode refletir as rotas aprendidas de um par IBGP para outros pares IBGP. Um RR é semelhante a um roteador designado (DR) em uma rede OSPF.
Cliente: um dispositivo IBGP cujas rotas são refletidas pelo RR para outros dispositivos IBGP. Em um AS, os clientes precisam apenas se conectar diretamente ao RR.
Não cliente: um dispositivo IBGP que não é um RR nem um cliente. Em um AS, um não cliente deve estabelecer conexões de malha completa com o RR e todos os outros não clientes.
Originador: é um dispositivo que origina rotas em um AS. O atributo Originator_ID ajuda a eliminar os loops de roteamento em um cluster.
Cluster: é um conjunto de RR e clientes. O atributo Cluster_List ajuda a eliminar os loops de roteamento entre os clusters.
Princípios Route-Reflector
Os clientes em um cluster precisam apenas trocar informações de roteamento com o RR no mesmo cluster. Portanto, os clientes precisam apenas estabelecer conexões IBGP com o RR. Isso reduz o número de conexões IBGP no cluster.
O RR permite que um dispositivo BGP anuncie as rotas BGP aprendidas de um par IBGP para outros pares IBGP e usa os atributos Cluster_List e Originator_ID para eliminar os loops de roteamento. O RR anuncia rotas para pares do IBGP com base nas seguintes regras:
O RR anuncia as rotas aprendidas de um não cliente para todos os clientes.
O RR anuncia as rotas aprendidas de um cliente para todos os outros clientes e todos os não clientes.
O RR anuncia as rotas aprendidas de um ponto EBGP para todos os clientes e não clientes.
Fórmula para redes full-mesh = n (n-1) / 2
Quando há um grande número de dispositivos, muitos recursos de rede e recursos da CPU são consumidos.Um refletor de rota (RR) pode ser usado entre pares do IBGP para resolver esse problema.
O Route Reflector encaminha as informações de roteamento recebidas de um cliente para outros clientes. Dessa maneira, todos os clientes podem receber informações de roteamento uns dos outros sem estabelecer sessões BGP.
Um roteador que não é um refletor de rota nem um cliente é um não-cliente, que deve estabelecer sessões BGP para o refletor de rota e outros não-clientes.
O refletor de rota e os clientes formam um cluster. Normalmente, um cluster possui um route reflector. O ID do route reflector é o Cluster_ID. É possível configurar mais de um route reflector em um cluster para melhorar a disponibilidade. Os route reflectors configurados devem ter o mesmo Cluster_ID para evitar loops de roteamento.
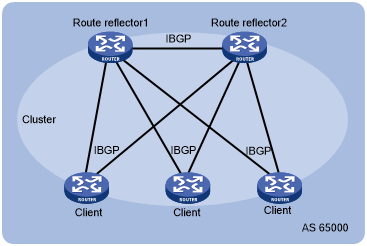
Route-Reflector (RR) de backup
Para garantir a confiabilidade da rede e evitar pontos únicos de falhas, RRs redundantes são necessários em um cluster. Um RR permite que um dispositivo BGP anuncie as rotas recebidas de um par IBGP para outros pares IBGP. Portanto, loops de roteamento podem ocorrer entre RRs no mesmo cluster. Para resolver esse problema, todos os RRs no cluster devem usar o mesmo ID do cluster.
RR1 e RR2 residem no mesmo cluster e têm o mesmo ID de cluster configurado.
Quando o Cliente1 recebe uma rota atualizada de um ponto EBGP, o Cliente1 anuncia essa rota para RR1 e RR2 usando o IBGP.
Depois que RR1 e RR2 recebem essa rota, eles adicionam o ID do cluster local à parte superior da lista de clusters da rota e refletem a rota para outros clientes (Cliente2 e Cliente3) e entre si.
Depois que RR1 e RR2 recebem a rota refletida um do outro, eles verificam a lista de clusters da rota, descobrindo que a lista de clusters contém seus IDs de clusters locais. RR1 e RR2 descartam essa rota para evitar loops de roteamento.
Quando os roteadores BGP em um AS são totalmente conectados com o ocnceito full-mesh, um router reflector é desnecessário porque consome mais recursos de largura de banda.
Atributo Cluster_List
Um RR e seus clientes formam um cluster, identificado por um ID de cluster exclusivo em um AS. Para evitar loops de roteamento entre clusters, um RR usa o atributo Cluster_List para registrar os IDs de cluster de todos os clusters pelos quais uma rota passa.
Quando uma rota é refletida por um RR pela primeira vez, o RR adiciona o ID do cluster local ao topo da lista de clusters. Se não houver uma lista de clusters, o RR criará um atributo Cluster_List.
Ao receber uma rota atualizada, o RR verifica a lista de clusters da rota. Se a lista de clusters contiver o ID do cluster local, o RR descartará a rota. Se a lista de clusters não contiver o ID do cluster local, o RR adicionará o ID do cluster local à lista de clusters e depois refletirá a rota.
Atributo Originator_ID
O ID do originador identifica o originador de uma rota e é gerado por um RR para evitar loops de roteamento em um cluster. Seu valor é o mesmo que o ID do roteador.
Quando uma rota é refletida por um RR pela primeira vez, o RR adiciona o atributo Originator_ID a essa rota. O atributo Originator_ID identifica o originador da rota. Se a rota contiver o atributo Originator_ID, o RR manterá esse atributo Originator_ID.
Quando um dispositivo recebe uma rota, ele compara o ID do originador da rota com o ID do roteador local. Se forem iguais, o dispositivo descarta a rota
Confederation BGP
Além de um router reflector a confederação é outro método que reduz o número de conexões IBGP em um AS. Uma confederação divide um AS em sub-ASs. As conexões IBGP full-mesh completa são estabelecidas em cada sub-AS. As conexões EBGP são estabelecidas entre sub-ASs. Os ASs fora de uma confederação ainda consideram a confederação como um AS. Depois que uma confederação divide um AS em sub-ASs, ele atribui um ID da confederação (o número do AS) a cada roteador dentro do AS. Isso traz dois benefícios. Primeiro, os atributos originais do IBGP são mantidos, incluindo o atributo Local_Pref, atributo MED e atributo Next_Hop. Em segundo lugar, os atributos relacionados à confederação são excluídos automaticamente ao serem anunciados fora de uma confederação. Portanto, o administrador não precisa configurar as regras para filtrar informações como números sub-AS na saída de uma confederação.

Dividir o AS em AS menores reduz o número de sessões IBGP de identificação, mas não é possível obter números AS adicionais.
Um AS é dividido em sub-ASs após a configuração de uma confederação. O número AS é usado como o ID da confederação. Para implementar a transmissão de rota e o encaminhamento de pacotes, as conexões IBGP serão necessárias se uma rede full-mesh completa.. Se a confederação for usada, apenas duas conexões IBGP e duas conexões EBGP serão necessárias. Portanto, o uso da confederação simplifica a configuração do dispositivo e reduz a carga de rede e CPU.
Além disso, os dispositivos BGP fora do AS conhecem apenas a existência do próprio AS, mas não a confederação dentro do AS. Portanto, a confederação não aumenta a carga da CPU.
A confederação precisa ser configurada em cada roteador, e o roteador que ingressa na confederação deve oferecer suporte à função de confederação.
Os speakers BGP precisam ser reconfigurados quando uma rede no modo de non-confederation muda para o modo de confederação. Como resultado, a topologia lógica muda de acordo.
Em redes BGP de grande escala, o RR e a confederação podem ser usados.
Route dampening (amortecimento)
· Projetado para reduzir a carga de processamento do roteador
causada por rotas instáveis.
· Minimiza a quantidade de processamento de atualização de BGP na
Internet, suprimindo rotas não selecionáveis (flapping)
· Não suprime (supress) rotas que ocasionalmente flap
· Suprimir(supress) rotas que provavelmente irão flap no futuro, com
base na história de seu comportamento.
A instabilidade da rota é refletida pelo route flapping. Quando uma rota é alterada, desaparece repetidamente da tabela de roteamento e depois reaparece.
Se ocorrer alteração de rota, um roteador envia um pacote de atualização para seus pares. Após os pares receberem o pacote Update, eles recalculam as rotas e atualizam suas tabelas de roteamento.
A troca frequente de rota consome muita largura de banda e recursos da CPU e pode até afetar as operações da rede.
O dampening de rota pode solucionar esse problema. Na maioria dos casos, o BGP é implantado em redes complexas nas quais as rotas mudam frequentemente. Para reduzir o impacto da troca frequente de rotas, o BGP adota o dampening de rotas para suprimir rotas instáveis.
O dampening BGP mede a estabilidade da rota usando um valor de penalidade - penalty value. Quanto maior o valor da penalidade, menos estável a rota. Cada vez que ocorre uma troca de rota (um dispositivo recebe um pacote de retirada ou atualização), o BGP adiciona um valor de penalidade à rota transportada no pacote.
Nota: O histórico possui um valor de timer, o valor do timer será decrescente e, depois que expirar, deixará de ser um histórico. Se as rotas baterem mais dentro desse tempo histórico, a rota será despejada e você deverá aguardar até que o cronômetro de despejo se esgote antes de continuar.
Se uma rota mudar de ativa para inativa, o valor da penalidade aumenta em 1000.
Se uma rota é atualizada quando está ativa, o valor da penalidade aumenta em 500.
Quando a penalidade excede o limite de supressão, a rota é interrompida (não é mais usada ou propagada a outros vizinhos).
Como resultado, o BGP não adiciona a rota à tabela de roteamento nem anuncia nenhuma mensagem de Atualização aos pares do BGP.
Uma rota nunca é interrompida por mais tempo que o limite máximo de tempo de supressão.
Uma rota inacessível com um histórico de flaps é colocada no estado de histórico - ela permanece na tabela BGP, mas apenas para manter o histórico de flap
Uma rota dampened é propagada quando a penalidade cai abaixo do limite de reutilização.
O histórico do flap é esquecido quando a penalidade cai abaixo da metade do limite de reutilização.
O Graceful restart (GR) é uma das tecnologias de alta disponibilidade (HA), que inclui uma série de tecnologias abrangentes, como redundância tolerante a falhas, proteção de link, recuperação de nó com falha e engenharia de tráfego. Como uma tecnologia de redundância tolerante a falhas, o GR garante o encaminhamento normal de dados durante o reinício dos protocolos de roteamento para impedir a interrupção dos principais serviços. Atualmente, o GR tem sido amplamente aplicado à comutação master/slave e atualização do sistema.
O GR geralmente é usado quando o RP (Processador de Rota Ativo) falha devido a um erro de software ou hardware ou usado por um administrador para executar a alternância de master/slave switchover.
Pré-requisito para Implementação
Em um dispositivo de roteamento tradicional, um processador implementa controle e encaminhamento. O processador encontra rotas com base em protocolos de roteamento e mantém a tabela de roteamento e a tabela de encaminhamento do dispositivo. Os dispositivos intermediários e avançados geralmente adotam a estrutura multi-RP para melhorar o desempenho e a confiabilidade do encaminhamento. O processador responsável pelos protocolos de roteamento está localizado na placa de controle principal, enquanto o processador responsável pelo encaminhamento de dados está localizado na placa de interface. O design ajuda a garantir a continuidade do encaminhamento de pacotes na placa de interface durante a reinicialização do processador principal. A tecnologia que separa o controle do encaminhamento atende ao pré-requisito para a implementação do GR.
Atualmente, um dispositivo compatível com GR deve ter duas placas de controle principais. Além disso, a placa de interface deve ter um processador e memória independentes.
Conceitos relacionados
Os conceitos relacionados ao GR são os seguintes:
GR Restarter: indica um dispositivo que realiza a alternância de master/slave acionada pelo administrador ou uma falha. Um GR Restarter deve suportar GR.
GR Helper: indica o vizinho de um GR Restarter. Um auxiliar de GR deve suportar GR.
GR Session: indica uma sessão, através da qual um GR Restarter e um GR Helper podem negociar recursos de GR.
Hora do GR: indica o horário em que o Auxiliar de GR descobre que o GR Restarter está inativo, mas mantém as informações ou rotas da topologia obtidas no GR Restarter.
End-of-RIB (EOR): indica informações de BGP, notificando um BGP de mesmo nível que a primeira atualização de rota é concluída após a negociação.
EOR timer: indica o tempo máximo de um dispositivo local aguardando as informações EOR enviadas do ponto. Se o dispositivo local não receber as informações de EOR do mesmo ponto no temporizador de EOR, o dispositivo local selecionará uma rota ideal das rotas atuais.
Princípios
Os princípios do BGP GR são os seguintes:
Durante o estabelecimento do relacionamento entre peers do BGP, os dispositivos negociam recursos de GR enviando recursos de GR suportados entre si.
Ao detectar a comutação master/slave do GR Restarter, um GR Restarter não exclui as informações de roteamento e encaminhamento de entradas relacionadas ao GR Restarter dentro do tempo de GR, mas aguarda para restabelecer uma conexão BGP com o GR Restarter.
Após a alternância master/slave o GR Restarter recebe rotas de todos os pares negociados com recursos de GR antes da alternância e inicia o temporizador EOR. O GR Restarter seleciona uma rota quando uma das seguintes condições for atendida:
O GR Restarter recebe as informações de EOR de todos os pares e o temporizador de EOR é excluído.
O temporizador EOR atinge o tempo limite, mas o GR Restarter não recebe informações de EOR de todos os pares.
O GR Restarter envia a rota ideal para o GR Helper e o GR Helper inicia o temporizador EOR. O Auxiliar de GR sai do GR quando uma das seguintes condições é atendida:
O GR Helper recebe as informações EOR do GR Restarter e o temporizador EOR é excluído.
O temporizador EOR atinge o tempo limite e o GR Helper não recebe informações EOR do GR Restarter.
GR Reset
Atualmente, o BGP não suporta negociação de capacidade dinâmica. Portanto, sempre que um novo recurso BGP (como os recursos IPv4, IPv6, VPNv4 e VPNv6) é ativado em um speaker BGP, o speaker BGP desativa as sessões existentes com seus pares e renegocia os recursos BGP. Esse processo interromperá os serviços em andamento.
Benefícios
Através do BGP GR, o encaminhamento não é interrompido. Além disso, o bater do BGP ocorre apenas nos vizinhos do GR Restarter e não ocorre em todo o domínio de roteamento. Isso é importante para o BGP que precisa processar um grande número de rotas.
BFD para BGP
O Border Gateway Protocol (BGP) envia periodicamente pacotes Keepalive a um par para monitorar o status do mesmo. No entanto, o BGP leva mais de 1 segundo para a detecção de falhas. Quando o tráfego é transmitido a taxas de gigabit, a detecção prolongada de falhas causa perda de pacotes, o que não atende aos requisitos de rede da operadora para alta confiabilidade.
Bidirectional Forwarding Detection - Detecção de Encaminhamento Bidirecional (BFD) para BGP pode detectar rapidamente falhas no link entre os pares de BGP e notificar o BGP sobre as falhas, o que implementa a convergência rápida da rota BGP.
O BFD está ativado para detectar o relacionamento de ponto EBGP entre o Dispositivo A e o Dispositivo B. Se o link entre o Dispositivo A e o Dispositivo B falhar, o BFD poderá detectar rapidamente a falha e notificar o BGP.
BGP 6PE
À medida que a tecnologia IPv6 se torna mais popular, um número crescente de redes IPv6 separadas toma forma. O IPv6 provider edge (6PE), uma tecnologia projetada para fornecer serviços IPv6 em redes IPv4, permite que os provedores de serviços forneçam serviços IPv6 sem construir redes de backbone IPv6. A solução 6PE conecta redes IPv6 separadas usando túneis MPLS (Multiprotocol Label Switching). A solução 6PE implementa a pilha dupla IPv4 / IPv6 nos dispositivos de borda do provedor (PEs) dos provedores de serviços da Internet e usa as extensões multiprotocolo para o protocolo Border Gateway (MP-BGP) para atribuir rótulos às rotas IPv6. Dessa maneira, a solução 6PE conecta redes IPv6 separadas por túneis IPv4 entre PEs.
Conceitos relacionados
Na aplicação prática, diferentes redes de área metropolitana (MANs) de um provedor de serviços ou redes de backbone colaborativas de diferentes provedores de serviços geralmente abrangem vários sistemas autônomos (AS).
A solução 6PE pode ser intra-AS 6PE ou inter-AS 6PE, dependendo se redes IPv6 separadas se conectam ao mesmo AS. O protocolo padrão fornece três modos inter-AS 6PE: inter-AS 6PE OptionB, inter-AS 6PE OptionB com roteadores de limite de sistema autônomo (ASBRs) como PEs e inter-AS OptionC. Esta seção descreve os seguintes modos 6PE:
Intra-AS 6PE: redes IPv6 separadas são conectadas pelo mesmo AS. Os PEs no AS trocam rotas IPv6 estabelecendo relacionamentos entre pares MP-IBGP.
Inter-AS 6PE OptionB: ASBRs em ASs diferentes trocam rotas IPv6 rotuladas estabelecendo relacionamentos de pares MP-EBGP.
Inter-AS 6PE OptionB (com ASBRs como PEs): ASBRs em diferentes ASs trocam rotas IPv6 usando MP-EBGP.
Inter-AS 6PE OptionC: PEs em ASs diferentes trocam rotas IPv6 rotuladas em sessões MP-EBGP de vários hop.
Outbound Route Filtering - A Filtragem de rota de saída (ORF) é usada para permitir que um dispositivo BGP envie a política de roteamento local para seu par BGP. O par pode usar a política de roteamento local para filtrar rotas indesejadas antes do anúncio da rota.
Na maioria dos casos, os usuários esperam que a operadora envie apenas as rotas necessárias. Portanto, a operadora precisa manter uma política de saída separada para cada usuário. O ORF permite que as transportadoras enviem apenas rotas necessárias para cada usuário sem manter uma política de saída separada para cada usuário. O ORF suporta anúncios de rotas sob demanda, o que reduz bastante o consumo de largura de banda e a carga de trabalho de configuração manual.
O ORF baseado em prefixo, definido em protocolos padrão, pode ser usado para enviar políticas de entrada baseadas em prefixo configuradas pelos usuários a uma operadora por meio de pacotes de atualização de rota. A transportadora filtra as rotas indesejadas antes do anúncio de rotas com base nas políticas de entrada recebidas, o que impede que os usuários recebam um grande número de rotas indesejadas e economiza recursos.
Sistema autônomo - AS (Autonomous System)

Um sistema autônomo (AS) é um grupo de redes IP (Internet Protocol) que são controladas por uma entidade, geralmente um provedor de serviços de Internet (ISP) e que possuem a mesma política de roteamento. Cada AS recebe um número AS exclusivo, que identifica um AS em uma rede BGP.
Dois tipos de números AS estão disponíveis:
Números AS de 2 bytes e números AS de 4 bytes.
Um número AS de 2 bytes varia de 1 a 65535 e um número AS de 4 bytes varia de 1 a 4294967295.
Os dispositivos que suportam números AS de 4 bytes são compatíveis com dispositivos que suportam números AS de 2 bytes.
Os sistemas autônomos de 1 a 64511 estão disponíveis pela IANA para uso global. As séries 64512 a 65535 são reservadas para fins particulares e reservados.
Sistemas autônomos foram introduzidos para regular organizações de rede, como Internet Service Providers (ISP), instituições educacionais e agências governamentais.
Sistemas autônomos foram introduzidos para regular organizações de rede, como Internet Service Providers (ISP), instituições educacionais e agências governamentais.
A IANA aloca Números de AS para registros regionais da Internet (RIRs). Os RIRs ainda alocam ou atribuem AS Números para operadores de rede, de acordo com as políticas RIR. Os [cinco RIRs] são:
- [AFRINIC]
- [APNIC]
- [ARIN]
- [LACNIC]
- [RIPE_NCC]
Atualmente, existem mais de 95.000 sistemas autônomos registrados.
História da ASN em nível mundial

Estatísticas da ASN por país

Referência:
Peering:
O peering (emparelhamento) é uma interconexão voluntária de redes da Internet, administrativamente separadas, tendo como o objetivo trocar tráfego entre os usuários de cada rede. A pura definição de peering é isenta de acordo, também conhecida como "bill-and-keep," or "sender keeps all,""faturar e manter" ou "remetente fica com tudo", o que significa que nenhuma das partes paga a outra em associação à troca de tráfego; em vez disso, cada um obtém e retém receita de seus próprios clientes.
Um acordo de duas ou mais redes com pares é instanciado por uma interconexão física das redes, uma troca de informações de roteamento por meio do protocolo de roteamento Border Gateway Protocol (BGP) e, em alguns casos especiais, um documento contratual formalizado.
Existem diferentes maneiras de entender a estrutura geral e a funcionalidade básica da Internet. Uma maneira de ver isso é considerá-lo como uma coleção de diferentes tipos de redes que podem ser (vagamente) categorizadas de acordo com seu tamanho e funcionalidade.
As três categorias principais são:
As três categorias principais são:
Redes de nível 1 [Tier 1] (ou redes globais) que compõem o núcleo da Internet. Atualmente, existem cerca de uma dúzia de redes de camada 1 na Internet. Sua tarefa é encaminhar pacotes isenta de acordo entre si. Ao conectar-se a uma ou mais redes de camada 1, sub-redes menores podem alcançar a maior parte da Internet sem precisar de um grande número de conexões.
Redes de nível 2 [Tier 2] (ou redes regionais) que participam do peering sem acordo, mas também compram ou vendem peering de / para outras redes. São conhecidas como redes de trânsito.
Redes de nível 3 [Tier 3] (ou redes locais) que operam exclusivamente comprando pares de redes de categoria superior.
Além desses três tipos de rede, a Internet inclui várias centenas de IXPs (Internet Exchange Points) que são usados para conectar ISPs entre si. No entanto, essas definições são apenas indicativas e são usadas principalmente para entender a estrutura da Internet, em vez de serem regras estritas.
As interconexões físicas usadas para o peering são categorizadas em dois tipos:
Peer público - interconexão utilizando uma malha de switches compartilhados de várias partes, como um switch Ethernet.
Peer privado - Interconexão utilizando um link ponto a ponto entre duas partes.
Topologia e roteamento da Internet
Compreender como os pacotes são transferidos de um nó em uma rede para outro requer algum conhecimento sobre a estrutura e a topologia da rede. A primeira coisa a entender é a diferença entre encaminhamento e roteamento. Como o nome sugere, o encaminhamento envolve a transmissão de um pacote de um link recebido para um link de saída dentro de um roteador. Pelo contrário, o roteamento envolve todas as etapas necessárias para encontrar a rota (ideal) entre dois nós. A idéia básica de roteamento na Internet é baseada em tabelas de encaminhamento em roteadores. Quando um host deseja enviar um pacote para um roteador, ele examina o destino e decide a próxima etapa com base no melhor valor correspondente em sua tabela de roteamento atual. Para enviar pacotes com precisão para o destino correto, as tabelas de roteamento são atualizadas constantemente conforme a rede muda.
O tamanho da Internet torna impossível para cada roteador manter uma lista de toda a rede. O roteamento hierárquico é usado para evitar problemas com escalabilidade e autonomia administrativa. Em vez de cada roteador funcionar individualmente, eles são divididos em grupos chamados sistemas autônomos. Cada AS tem um número de sistema autônomo (ASN) único de 16 ou 32 bits e é mantido por um grupo definido de administradores. Todos os roteadores de um AS usam o mesmo protocolo de roteamento intra-autônomo do sistema para se comunicar, e todos conhecem os outros roteadores pertencentes ao mesmo sistema.
A alocação de números AS é feita de maneira semelhante aos endereços IP: a IANA aloca números como blocos para os RIRs que os atribuem aos operadores de rede.
Na extremidade de cada AS existe um ou mais roteadores de gateway responsáveis pela comunicação com outros AS. Isso permite que cada AS use seus protocolos de roteamento preferido para comunicação interna, desde que os roteadores de gateway de todos os ASs da rede usem o mesmo protocolo de roteamento inter-AS para mover pacotes entre sistemas.
Paragéns!, Ótima explicação quanto ao funcionamento do Protoloco!
ResponderExcluir